Como es costumbre, os dejo aquí mi presentación del artículo de EUMAS '09. Que el título no engañe: habla más de MDD que de sistemas limitados aunque el ejemplo que ponemos sea de Android. Esta vez me ha costado mucho terminarla y aún así el resultado tampoco me convence demasiado... la he reordenador un millón de veces.
Applying Model Driven Development in MAS for limited devices
↧
↧
EUMAS 09. Session 6. Negotiation, Dialog and Laws
Managing quality in agent dialogues
Josep Puyol-Gruart
Measuring the quality of answers in agent's conversations. Quality measures:
precision (smaller interval) and certainly (how close is to true or false). They are related: precision is more interesting when certainly is close to true or false. Talking about absolute (values for the facts) and relative (external view) quality. But explaining all these thing he's run out of time, so he can't explain how agents can use this quality measures.
Designing Automated Agents Capable of Efficiently Negotiating with People - Overcoming the Challenge
Raz Lin
It's very difficult to design domain independent agents that negotiate with other agents or with people, and this is the goal of the paper. HE establihes the negotiation environment, how the agent isdesigned and shows some samples in games andother environments: Diplomacy, autONA, Cliff-Edge... finishing with the KBAgent, which includes all the characteristics developed in the previous ones
- Generic agent / domain independent
- Qualitative decision making
- Non deterministic behavior / randomization
- Incorporating data from past interactions
And now something about validation. It is a problem because it is no standard fto do that. What is a 'good' agent? maximal payoff/maximal social welfare/end with agreement/pass Turing test? This is an open question.
A good question from Ingrid Nunes abuot emotions, because their influence in human negotiations. But at the moment they are not taken into account
Blogged with the Flock Browser
↧
Thomas. A Service Oriented Framework for Virtual Organizations
Es el título de la demo que hemos mandado al AAMAS 2010. Thomas es entorno que permite formar organizaciones virtuales abiertas que pueden evolucionar con el tiempo y permiten a los agentes inteligentes registrarse en ellas e interactuar con el resto de agentes a traves, principalmente, de la invocación de servicios.
Como el vídeo incluye pantallas de la aplicación, se ve mejor en pantalla completa o directamente la versión en HD en vimeo.
Sobre todo, gracias a Elena y a Natalia por el esfuerzo en tenerlo todo listo a tiempo.
↧
Agreement Technologies and Social Neuroscience
Los días 18 y 19 de febrero tendrá lugar el workshop Agreement Technologies and Social Neuroscience, organizado dentro del proyecto Agreement Technologies. Se trata de un workshop multidiciplinar para tratar de comprender mejor cómo se pueden modelar acuerdos dentro de un contexto social entre
El año pasado asistí y la verdad es que resultó muy interesante: hablar con expertos de áreas que no tienen que ver nada con la mía... ni siquiera con la informática, descoloca un poco pero es muy enriquecedor. Si te gustan estas cosas te recomiendo que vayas. Si hay hueco, yo pretendo ir.
Si quieres saber algo más, aquí tienes el programa y los resúmenes de las ponencias.... y no voy a escribir más frases que empiecen con "si".
↧
DCAI '10 Call for papers
The International Symposium on Distributed Computing and Artificial Intelligence (DCAI 2010) is an annual forum that will bring together ideas, projects, lessons, etc.. associated with distributed computing, artificial intelligence and its applications in different themes. The workshop will be organized into CEDI 2010 that will be held at the Polytechnic University of Valencia in September 7-10th, 2010.
This symposium will be organized by the Biomedicine, Intelligent System and Educational Technology Reseach Group (BISITE) of the University of Salamanca. The technology transfer in this field is still a challenge and for that reason this type of contributions will be specially considered in this symposium. This conference is the forum in which to present application of innovative techniques to complex problems.
The artificial intelligence is changing our society. Its application in distributed environments, such as the Internet, electronic commerce, mobile communications, wireless devices, distributed computing, and so on is increasing and is becoming an element of high added value and economic potential, both industrial and research. These technologies are changing constantly as a result of the large research and technical effort being undertaken in both universities and businesses. The exchange of ideas between scientists and technicians from both academic and business areas is essential to facilitate the development of systems that meet the demands of today's society.
DCAI 2010 is sponsored by the IEEE Systems Man and Cybernetics Society, Spain Section Chapter. The accepted papers included in DCAI 2010 proceedings (long papers, short papers and doctoral consortium papers) will be published by Springer Verlag in the Advances in Intelligent and Soft-Computing series of Springer. At least one of the authors will be required to register and attend the symposium to present the paper in order to include the paper in the conference proceedings.
↧
↧
Consensus Networks as Agreement Mechanism for Autonomous Agents in Water Markets
Es el título de nuestro paper en las Jornadas que organiza el $latex im^2$ (Instituto de Matemática Multidisciplinar) de la UPV: Mathematical Models for Addictive Behaviour, Medicine & Engineering. El tema es el uso de redes de consenso para alcanzar acuerdos de forma descentralizada, aplicado en concreto a problemas de gestión de recursos hídricos. A continuación te dejo el resumen (en inglés) y las trasparencias de la presentación. En cuanto esté publicado dejaré también la referencia completa al artículo y, si puedo por temas de licencia, el enlace.
Abstract
The aim of this paper is to present a way of share opinions in a decentralized way by a set of agents that try to achieve an agreement by means of a Consensus Network, allowing them to know beforehand if there is possibilities to achieve such an agreement or not.
The theoretical framework for solving consensus problems in dynamic networks of agents was formally introduced by Olfati-Saber and Murray (2004). The interaction topology of the agents is represented using directed graphs and a consensus means to reach an agreement regarding a certain quantity of interest that depends on the state of all agents in the network. This value represents the variable of interest in our problem.
A consensus network is a dynamic system that evolves in time. Consensus of complete network is reached if and only if $latex x_i = x_j \forall i, j$. Has been de demonstrated that a convergent and distributed consensus algorithm in discrete-time can be written as follows:
$latex x_i(k+1)=x_i(k) + \varepsilon \sum_{j \in N_i} a_{ij}(x_j(k)-x_i(k))$
where $latex N_i$ denotes the set formed by all nodes connected to the node i (neighbors of i). The collective dynamics of the network for this algorithm can be written as $latex x(k+1)=Px(k)$, where $latex P=I-\varepsilon L$ is the Perron matrix of a graph with parameter $latex \varepsilon$. The algorithm converges to the average (or other functions) of the initial values of the state of each agent and allows computing the average for very large networks via local communication with their neighbors on a graph.
The convergence of this method depends on the topology of the network and its convergence is usually exponential. But sometimes it not needed to reach a final agreement on a concrete value. This proposal uses consensus networks to determine if an agreement is possible among a set of entities. Agents can leave the agreement if its parameters are out of the expected bounds, so the consensus network can be used to detect the candidate agents to be members of the final agreement. All this process is solved in a self-organized way and each individual agent decides to belong or not to the final solution.
To show the validity of the present approach, a water market is presented as case of study. The water market is a case of complex social-ecological system (SES), where centralized and hierarchical approaches trend to fail and self-organized solutions seems to be more sustainable in the long term (Ostrom, 2009). In general, agreements related to natural resource management involve very complex negotiations among agents. Water demands and regulation is a very complex distributed domain appropriated for MAS.
An important question is if this kind of markets requires some regulation or not. From an exclusively economic point of view the dominant strategy for agents in deregulated markets is not cooperative because each agent wants to maximize exclusively his payoff, and therefore they are not interested in the global and socially efficiency of the natural resources.
↧
[CostAT] Coherence-based argumentation models for normative agents
Abstract :
In this talk coherence-based models are proposed as an alternative to argumentation models for the reasoning of normative agents and normative deliberation. The model is based on Thagard’s theory of cognitive coherence and exploits the coherence relations that exist between claims and conclusion of arguments. A coherence-based model is intended to introduce more flexibility in the process of deliberation and agreement generation among normative agents. The basic coherence philosophy and what makes it interesting in the context of normative agents that deliberate to regulate a domain of interest are discussed.
This paper shows the application of coherence models to an argumentation model in a normative, regulated environment. I'm interested not in tris particular application, but in the coherence theory (Thagard).
Coherence estudies associations between pieces of information. It tríes to separate information in sets that mutually support the data. In some way, it can be consideres as a constraint satisfacción problem.
Different types of coherence can be identified: deductive, explanatory, deliberative, analoogous or conceptual, depending on the type of information. The Thagard model is a model of deductive coherence. It can be considered as a constraint satisfacción problem. But the main difference is that it does not try to maximize the partition (not the optimal -it is not needed to find a solution-)
Coherence applied to argumentation sees positive relates info as supporting arguments and negative weights as attacks to a claim.
Problem (general) How the coherence weights are calculated? Well, it is addressed in the questions: depends (roughly) on the number of arguments supporting a hypothesis.
Something interesting in the conclusiones: it can model different tupes of agente (utility maximizares, norm abiders, altruistic...) What about diferentt personalities? And a possibility for us: introduction of contexto as part of the future work.
More infomration, read Sindhu Jospeh PhD. thesis, "Copherence-Based Computational Agency"
↧
[CostAT] Trust as a Unifying Basis for Social Computing
by Munindar Signh
Trust underlies all interactions among autonomous parties over many social relationships: casual, familiar, communal, organizational, practical.... But trust it use to be a internal characteristics and it can not be extrapolated outside a single application.
A social applications specifies and configure (i) roles,, (Ii) social interactions and (iii) additional constraints. And the elements we have available to model these systems (architecture) are components, connectors, constraints (over both of them) and patterns (that generalize its behavior). In the case of a social systems, they are
components >> individuals
connector >> social relationships
constraint >> reciprocal (ej Facebook)
patterns >> ....
The claim of this presentations is that trust is what flues in the relationships and it is how individuals and social relationships can be characterized. The sample> an agent (Toto) that acts as a middleware and can provide with trust the interactions among real people in different applications. That is, a layer which can be used in social apps (for instance) to measure the confidence on other users (humans) interactions (NOTE. a very close concept to the trust bundle proposed in AT)
↧
[EUMAS10] J-MADeM v1.0: A full-fledge AgentSpeak(L) multimodal social decision library in Jason
Trying to produce social intelligent agents that shows an acceptable behaviour in social envinronments. Applied to BDI agents and using an auction model as decision/making mechanism. It seems interesting for us, as the last step for reaching a concrete agreement after an agreement space has been created using a consensus network. And it is implemented over Jason, so we can integrate it in Mgx agents.
The API seems to extend a Jason agent with predicates that can be introducced in the rules. So if we get a network of jason-mgx agents, we can program agents with decision making procedires that maximizes the benefit of a concrete water rights distribution among participants.
An interesting work that can be useful for us. I'll read the paper later
↧
↧
Detección de comunidades en redes mediante consenso
 Estos días he estado en la International School and Conference on Network Science (NetSci '15). Era la primera vez que asistía a esta conferencia y la verdad es que me ha parecido muy interesante. Es un campo todavía nuevo para mi y apenas conozco a nadie, pero bueno, poco a poco.
Estos días he estado en la International School and Conference on Network Science (NetSci '15). Era la primera vez que asistía a esta conferencia y la verdad es que me ha parecido muy interesante. Es un campo todavía nuevo para mi y apenas conozco a nadie, pero bueno, poco a poco.
El jueves presenté una de las cosas en las que estoy trabajando: los procesos de consenso en redes para tomar decisiones. Y esta vez, aplicado a la detección de comunidades de forma autónoma. La detección de comunidades es un problema conocido en el campo de las redes. Se trata de, dada una red (por ejemplo, conversaciones en Twitter, contactos en Facebook, pero también colaboraciones en artículos científicos o conexiones entre ciudades), detectar los grupos que existen en ella. Normalmente, hay un grupo cuando un conjunto de nodos de la red está más conectado entre sí que con el resto de la red, es decir, los grupos o las comunidades se detectan atendiendo a la densidad de las conexiones (alta dentro del grupo, baja entre grupos).
El método que he presentado tiene algunas diferencias:
- usa redes con signo: es decir, los enlaces pueden ser positivos o negativos, indicando relaciones de amistad/enemistad, me gusta/no me gusta, etc.
- no necesita saber de antemano cuántas comunidades existen
- trabaja con información local: cada nodo de la red solo conoce su propia información y la de sus vecinos directos. No sabe nada sobre el tamaño de la red, su estructura o ninguna otra característica global.
El proceso comienza asignando un valor aleatorio x a cada nodo. Se ejecuta el proceso de consenso (tratando de acercarse al valor de los vecinos) hasta que converge (no hay diferencias entre una iteración y la anterior). El resultado del proceso de consenso es la división de la red en dos grupos según el signo del valor final: aquellos con x > 0 pertenecen a un grupo y los que tienen x < 0 al otro. Si necesitamos hacer más divisiones, simplemente repetimos el proceso hasta que no haya más divisiones.
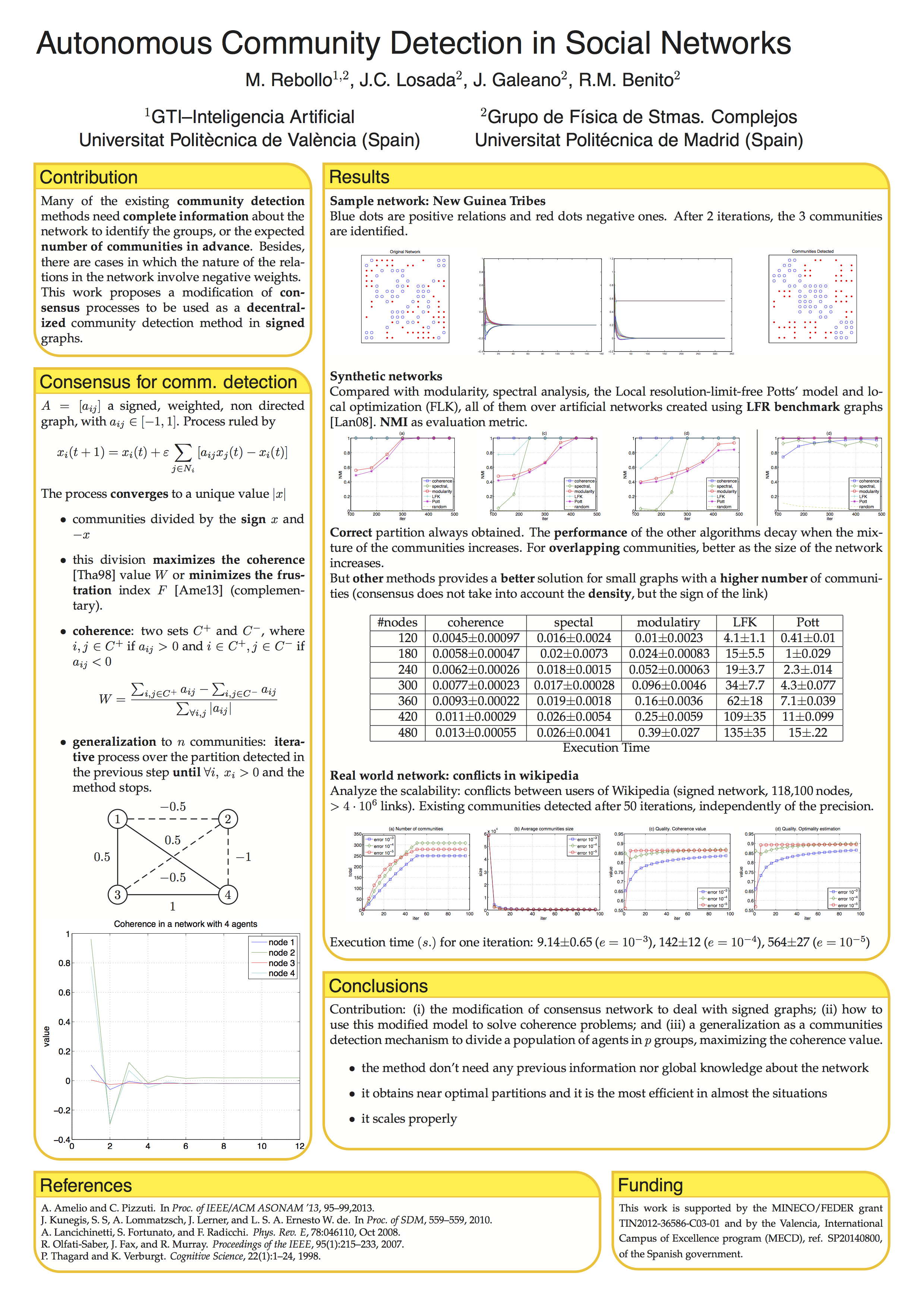
Hemos probado con algunos ejemplos conocidos, como la red que modela las relaciones entre tribus de Nueva Guinea y se detectan correctamente las 3 comunidades que existen realmente.
Para comprobar el rendimiento, hemos empleado un benchmark de detección de comunidades y hemos comparado nuestros resultados con otros métodos bien conocidos (ver el póster). El resultado es que el método que proponemos funciona mejor cuanto mayores son las redes. Cuando hay mucha mezcla entre grupos también funciona mejor que el resto. El único caso en el que obtiene peores resultados es para redes pequeñas y cuando hay un número elevado de comunidades. En cuanto al tiempo de ejecución, ahí el método es más eficiente que todos los demás con diferencia, sacando al menos un orden de magnitud (10 veces menos) al siguiente mejor método, y llegando a ser casi 10.000 veces más rápido que otras técnicas habituales (para redes de 500 nodos)
Por último, para comprobar si escala bien a redes grandes, lo hemos aplicado al dataset sobre conflictos en la Wikipedia. Es una red con más de 100.000 nodos y unos 4 millones de enlaces. Nuestro método sigue comportándose bien.
Algo que queda por hacer, es modificarlo para que sea capaz de obtener las comunidades en redes dinámicas, es decir, que la red cambie mientras se construyen las comunidades y que los grupos cambien cuando la red se modifique. Ya tenemos resultados en ese sentido que simplemente hay que adaptar para este caso. Otro tema es, en lugar de construir el grupo atendiendo a un criterio x, tratar de construir las comunidades a partir de varias dimensiones (x1, x2, x3,…) De nuevo, también es algo en lo que estamos trabajando y que posiblemente en unos meses podamos aplicar a este caso también.
Os dejo una copia del póster, por si a alguien le interesa (pincha en la imagen para verlo en grande)
↧
AHP descentralizado en redes multicapa mediante consenso
 Más o menos es la traducción del trabajo que he presentado esta semana en el PAAMS'16, que se está celebrando del 1 al 3 de junio en la Escuela de Informática de la Universidad de Sevilla.
Más o menos es la traducción del trabajo que he presentado esta semana en el PAAMS'16, que se está celebrando del 1 al 3 de junio en la Escuela de Informática de la Universidad de Sevilla.
Los procesos analíticos jerárquicos se emplean para la toma de decisiones complejas en la que intervienen muchos factores (decisiones multi-criterio); por ejemplo, la valoración de jugadores de fútbol, pero también obras de arte, patentes, empresas... En nuestro caso, el problema se complica ya que
- la decision no es individual, sino de un grupo que tiene que llegar a un acuerdo (la mejor solución para todos)
- cada criterio tiene un valor distinto para cada persona, y se mantiene privado (nadie sabe qué es más importante o menos para el resto de miembros del grupo)
- todos los miembros del grupo no se conocen entre sí, sino que cada persona solo conoce a algunos miembros. El grupo realmente es una red, como la que se forma en las redes sociales
Nuestra solución combina dos métodos: un proceso de consenso en cada uno de los criterios para tratar de llegar a la solución común, más un proceso de ascenso por gradiente que trata de compensar lo que cedo en uno de los criterios al grupo en algún otro criterio que sea importante para mi.
Al final, bajo determinadas condiciones (que son bastante razonables), se puede garantizar que el proceso converge a la mejor decisión posible, que es la que maximiza el valor.
Es importante remarcar que nadie sabe dónde está este valor, pero se aproximan a él en grupo al tratar de acercarse a los demás (consenso) pero tratando de mantener los valores mejores para cada miembro del grupo.
Os dejo aquí las transparencias de la charla y la referencia al artículo
Rebollo, M., A. Palomares, C. Carrascosa. Decentralized Group Analytical Hierarchical Process on Multilayer Networks by Consensus. In Advances in Practical Applications of Scalable Multi-agent Systems, pp. 183-194. doi:10.1007/978-3-319-39324-7_16, 2016
↧
U-Tool: herramienta para analizar la actividad de los ciudadanos
Otro de los trabajos que presentamos en la pasada conferencia PAAMS '16 fue la demo de una herramienta creada por Javier Palanca y Elena del Val. Lo que empezó como una herramienta para recopilar tuits de forma automática (privada) y una web para analizar la actividad de la ciudad durante las Fallas (www.buscafallas.com), se han acabado uniendo (y ampliando) en un proyecto que se está integrando en el portal de Datos abiertos del Ayuntamiento de Valencia.
La herramienta permite seguir una etiqueta en Twitter o los tuits geolocalizados que se publican en un área determinada. Los datos recopilados se muestran en un mapa para ver la densidad de tuits, un grafo que muestra las conversaciones, o la principal aportación: un mapa gravitacional en el que se refleja como determinadas zonas de la ciudad atraen a las personas y las trayectorias que se siguen para desplazarse de unos sitios a otros.
Aquí están las transparencias de la presentación. Es una versión modificada, con algo más de texto para que sean autoexplicativas.
↧
Análisis de sentimientos en Twitter con HMM
 Es el título de mi charla en el Comunica 2: un congreso que se celebra todos los años por esas fechas en la EPS de Gandía sobre comunicación y redes sociales. En ella, hablé de un proyecto en el que estamos trabajando: analizar los sentimientos que aparecen en los mensajes en las redes sociales.
Es el título de mi charla en el Comunica 2: un congreso que se celebra todos los años por esas fechas en la EPS de Gandía sobre comunicación y redes sociales. En ella, hablé de un proyecto en el que estamos trabajando: analizar los sentimientos que aparecen en los mensajes en las redes sociales.
La hipótesis de partida es que los tuits no demuestran cual es el sentimiento real de los usuarios. Al menos no siempre. En ocasiones, yo puedo estar con un estado de ánimo determinado, pero escribir un mensaje que expresa una emoción distinta.
Para poder analizarlo, usamos modelos ocultos de Markov (HMM). En estos modelos hay dos tipos de estados: unos ocultos, que no podemos conocer, y otros observables. El ejemplo que se suele poner en estos casos es el siguiente: piensa que nuestro amigo vive en una ciudad distinta. Nosotros no sabemos qué tiempo hace allí (si llueve o hace sol -oculto-), pero sí qué es lo que ha hecho nuestro amigo ese día (correr, ir de compras o hacer las tarea de la casa -observable-). Si conocemos las probabilidades de que nuestro amigo corra o salga de compras en cada caso, podríamos tratar de estimar qué tiempo hace en su ciudad.
Eso mismo hacemos con los sentimientos: nosotros no vemos el sentimiento de la persona (oculto), pero si su expresión a través de un tuit (observable), así que tratamos de determinar el sentimiento de los usuarios a través de la secuencia de tuits que escribe.
El modelo que usamos para determinar el sentimiento es el modelo de Russell, que asocia dos valores: valencia (positivo o negativo) y arousal (activo/pasivo). Estos valores se pueden representar en un sistema de coordenadas y determinar el sentimiento que le corresponde según su posición.
Con todo eso, lo que hacemos es
- descargar los tuits de un determinado evento, es decir, los que contienen una determinada etiqueta (hashtag)
- extraer de cada tuit las palabras que tienen carga emocional y asignarles el valor de valencia y arousal que le corresponde (usamos el diccionario ANEW).
- crear la red que modela la conversación del evento. Si un mensaje es una mención, una respuesta (reply) o un retuit, creamos un enlace entre los dos usuarios (eso se usa luego para inicializar el HMM)
- construir las secuencias de tuits para cada usuario. Dividimos estas secuencias en dos partes: el 80% para entrenar el modelo y el 20% para validarlo
- entrenar el modelo usando el conjunto de secuencias de entrenamiento. Eso nos da unas probabilidades de pasar de un sentimiento a otro y de, dado un sentimiento, publicar un tuit con una emoción un otra.
- validar el modelo con las secuencias de test que quedan
El resultado obtenido muestra que, en general, los HMM funcionan mejor que los modelos de Markov "normales", sin estados ocultos. Es decir, que considerar por separado el sentimiento real del usuario de la emoción que muestra en un tuit explica mejor cómo evolucionan los sentimientos de los usuarios y qué emoción aparece en los tuits. Además, esta diferencia es mayor en eventos en los que no hay un sentimiento mayoritario.
El artículo completo aparecerá en las actas del congreso. Mientras, te dejo las transparencias que usé en la charla
(imagen: Ryan McGuire, public domain)
↧
↧
Identificación de grupos mediante reputación
Los días 21 y 22 de febrero está teniendo lugar la III edición de Comunica2.0 y voy a presentar un trabajo en el que se analizo cómo se pueden identificar grupos dentro de una red de acuerdo a su opinión, cuando éstas son positivas o negativas. La propuesta es aplicar procesos de consenso pero con la particularidad de que la red es una rd con signo, es decir, los pesos entre dos nodos están comprendidos entre -1 y 1.
La entrada Identificación de grupos mediante reputación se publicó primero en Miguel Rebollo.
↧
Uso de redes sociales en el aprendizaje inverso
La entrada Uso de redes sociales en el aprendizaje inverso se publicó primero en Miguel Rebollo.
↧
50 anys, i les dones?

Los días 6 y 7 se han celebrado en la UPV las Jornadas feministas organizadas por MouT e Hipnopèdia urbana, en las que se habló del papel de las mujeres en la ciencia, el urbanismo y la movilidad, entre otros temas.
Y allí estaba yo, como un pato en el Manzanares, dispuesto a dejarme enseñar. Y vaya si aprendí.
El primer día fue más general y se habló al final sobre todo de urbanismo. Empezó Cristina Furió hablando de Feminismo, así, con mayúsculas. Poniéndolo en contexto, enseñando una parte de la historia que hasta ahora nunca había visto, confieso mi más completa ignorancia.
Después Eulalia Gómez nos abrumó con sus cifras y letras acerca de la mujer en la academia y con ejemplos claros, con datos, de la marginación real y el sexismo que existe en una institución como la mía, de lo que me avergüenzo enormemente. Algo como la ciencia, neutro y objetivo, acaba teniendo unos sesgos brutales que no se ven. Y algo curioso para mi: en el campo de la Informática, ell cambio de nombre de Licenciatura a Ingeniería hizo que, de repente, el número de mujeres matriculadas cayera del 40% al 13% en apenas dos años. ¿correlación o causalidad?
Luego llegó la charla que más me impactó: la de Inés Novella, hablando de mujeres en las carreras STEM. Y aunque se centró más en la Arquitectura, todo lo que dijo a mi me sirvió. Básicamente, sin igualdad no puede haber excelencia. Y el problema de nuestras carreras es que la I+D no incorpora el género. Aunque en el FP7 se ha intentado corregir y ahora es algo obligatorio para los proyectos del H2020. Y por su culpa ahora me he dado cuenta de todo lo que he estado haciendo mal en mi investigación, y que os contaré en alguna entrada en breve.
La sesión la cerró natalia García hablando de Sostre, de los paseos de Jane y del proyecto Genera Barri, cuestionando si todos tenemos acceso a los mismos recursos de la ciudad y las mismas necesidades, explicando como integrar la perspectiva de género en el uso de la ciudad. La jornada acabó con una mesa redonda con todas la ponentes. Debíamos estar a gusto, porque se suponía que iba a acabar a las 8 y estuvimos casi hasta las 9 y media :-)
La segunda jornada fue vertiginosa. Apenas me dio tiempo a tomar notas. Pero de todas formas he estado tan absorto con las charlas que las notas apenas me sirven para recordar lo fundamental dentro de un tiempo. Pero tampoco hace falta, porque lo que escuché me ha calado dentro. Luego quizá no recuerde nombres y datos, pero eso es secundario y se puede volver a encontrar en cualquier momento.
El día empezó con Eva Álvarez contando cómo sería una ciudad no sexista según la visión de Dolores Hayden, expuesta en su artículo What Would a Non-Sexist City Look Like? Speculations on Housing, Urban Design, and Human Work. Un documento denso, técnico, pero que cuando tenga tiempo quiero leer despacio.
Luego Nel·la Saborit nos puso a los hombres en nuestro sitio. Porque tengo que reconocer que las jornadas, en general, fueron un tanto asépticas, muy cerebrales, politécnicas. Seguro que alguna de las que estuvisteis allí echasteis de menos un enfoque más reivindicativo. La charla de Nel·la fue la otra que me hizo ver lo que estoy haciendo mal. Hablaba de la cautividad de la mujer y el transporte público. Los movimientos de las mujeres cuando se desplazan por la ciudad siguen unos patrones muy claros, lo que se llaman desplazamientos poligonales. Uno de los proyectos en los que trabajo consiste en analizar los movimientos de las personas en la ciudad a través de Twitter. Y justamente habíamos eliminado desplazamientos con esas formas porque nos complicaban el modelo. Bueno, realmente no los eliminamos, sino que los partimos en tramos rectilíneos (o con curvas abiertas). Esto lo tendremos que revisar.
La tercera fue Mariola Fortuño hablando de movilidad inclusiva y urbanismo feminista, argumentando que la igualdad se consigue con la autonomía en los desplazamientos diarios. Habló de muchas cosas, pero a mi me quedó pendiente ver La bicicleta verde, una película Saudí que trata de una niña que quiere tener una bicicleta y a la que no se le permite.
A continuación Belén Calahorro analizó el uso de la bicicleta por parte de las mujeres. Ya estaba claro que las mujeres os movéis de una forma distinta en la ciudad: más lentas, en distancias más cortas y con un mayor número de desplazamientos. Excepto en los países obvios, el uso de la bicicleta por parte de la mujer es minoritario. Uno de los motivos principales es el sentimiento de inseguridad y las iniciativas actuales en cuanto a mejora de las infraestructuras, no parecen suficientes.
Las charlas acabaron con la de Maria Oliver repasando el papel de las mujeres en los movimientos vecinales y tratando de convencer a las mujeres de la necesidad de formar parte activa de la política.
No me pude quedar a la mesa redonda del último día, pero seguro que fue como la del primero.
Para acabar, solo puedo daros las gracias, a Cristina por abrirme los ojos, a Inés por enseñarme nuevas posibilidades en mi carrera y a todas las demás por hacerme sentir tan pequeño.
La entrada 50 anys, i les dones? se publicó primero en Miguel Rebollo.
↧
Procesos de consenso con nodos tramposos

Hace unas semanas tuvo lugar el XIII Congreso de Física Estadística: uno de los congresos a los que asisto regularmente desde que empecé el Master en Física de Sistemas Complejos. Esta vez fue en Sevilla y presenté un par de trabajos: de uno de ellos ya os he adelantado cosas porque es la parte más técnica del análisis de sentimientos en Twitter que conté en Comunica2, así que no me voy a repetir. Pero el otro trabajo es algo nuevo de este verano: detectar nodos que no siguen el proceso de consenso.
Los procesos de consenso en redes consisten en tratar que un conjunto de nodos de una red, como usuarios en Twitter o Facebook, una red de sensores (por ejemplo, los termómetros en una ciudad o los contadores eléctricos), o cualquier grupo organizado en forma de red, es capaz de realizar cálculos de forma distribuida sin que haya ningún nodo central que los coordine.
Por ejemplo, para calcular la temperatura de una ciudad, podemos tener muchos termómetros repartidos por ella y todos ellos mandan sus medidas de temperatura a un ordenador central que hace la media y nos dice que temperatura hace.
Pues bien, los procesos de consenso permitirían a cada termómetro calcular de forma autónoma ese valor medio de temperatura sin más que intercambiando su propia medida con los vecinos directos y actualizando su valor según esta fórmula:
![x_i(t+1) = x_i(t) + \epsilon \sum_{j \in N_i}[x_j(t) - x_i(t)]](http://s0.wp.com/latex.php?latex=x_i%28t%2B1%29+%3D+x_i%28t%29+%2B+%5Cepsilon+%5Csum_%7Bj+%5Cin+N_i%7D%5Bx_j%28t%29+-+x_i%28t%29%5D&bg=ffffff&fg=000&s=0 "x_i(t+1) = x_i(t) + \epsilon \sum_{j \in N_i}[x_j(t) - x_i(t)]")
Pero para que funcione, se asume que todos los termómetros tienen que hacer lo mismo. Pero ¿qué ocurre si alguno falla? ¿o si alguien, de forma malintencionada, quiere alterar el cálculo?. Un resultado conocido es que, si uno de los nodos de la red no cambia su valor (por ejemplo, pasa a sus vecinos siempre 22º C), el valor medio final es el valor de ese nodo (todos pensarían que la temperatura media es de 22º C).
El trabajo que presenté en el Fises es parte de mi tesis y en él demuestro que
- se puede detectar cuando algún nodo de la red no sigue correctamente el proceso de consenso
- se puede corregir el valor defectuoso de forma que se calcule el valor correcto
- en determinadas condiciones, incluso se puede detectar qué nodo es el que está funcionando mal
Estoy terminando un artículo con los detalles. Mientras, te dejo el póster que envié al congreso (pincha en la imagen para verla más grande).

La entrada Procesos de consenso con nodos tramposos se publicó primero en Miguel Rebollo.
↧
↧
Transport Network Analysis for Smart Open Fleets
 Estos días estoy en Oporto, en el 15th International Conference on Practical Applications of Agents and Multi-Agent Systems (PAAMS'17) y este es el título de una de mis charlas.
Estos días estoy en Oporto, en el 15th International Conference on Practical Applications of Agents and Multi-Agent Systems (PAAMS'17) y este es el título de una de mis charlas.
La idea es que los usuarios particulares actúen como transportistas aprovechando sus viajes diarios. Una especie de Uber para mensajería. Para ello, se crean flotas ciertas, formadas por una gran variedad de vehículos que se unen y abandonan la red atendiendo a la disponibilidad de los usuarios particulares. Estas flotas estarán formadas por una combinación de vehículos comerciales, taxis, coches particulares, motos, bicicletas, transporte público (metro y bus) o incluso peatones. Una persona que necesite enviar un paquete lo entregará a un usuario de la red cercano (un vecino, un compañero de trabajo…) y este lo entregará al destinatario final si va a coincidir con él o a otro transportista que se encuentre más cerca de ese destinatario final.
Para poder realizar el servicio de forma eficiente, el framework propuesto por Billhard et al (2016) se amplia con un módulo de análisis de redes (TNAM), encargado de estudiar la estructura de la red de transporte y asegurar que se dan las condiciones para que el servicio se proporciones de manera eficaz.
Se estudia como caso de aplicación la red de transporte de Valencia, centrándose en la red de estaciones del servicio de alquiler de bicicletas. Se caracteriza la red y se estudia us eficiencia, comparándola con la eficiencia de las redes de otras ciudades como Madrid o Salamanca. La conclusión es que se trata de una red robusta ante fallos, tanto aleatorios como ataque deliberados a las estaciones más relevantes. El análisis se puede replicar para las distintas capas que configuran los medios de transporte público disponibles en la ciudad: metro, bus, bicicletas y taxi.
Se puede acceder al artículo completo a través de la referencia siguiente
Rebollo M., Carrascosa C., Julian V. (2017) Transport Network Analysis for Smart Open Fleets. In: Bajo J. et al. (eds) Highlights of Practical Applications of Cyber-Physical Multi-Agent Systems. PAAMS 2017. Communications in Computer and Information Science, vol 722. Springer, Cham
La entrada Transport Network Analysis for Smart Open Fleets se publicó primero en Miguel Rebollo.
↧
Using geo-tagged sentiment to better understand social interactions
 Estos días estoy en Oporto, en el 15th International Conference on Practical Applications of Agents and Multi-Agent Systems (PAAMS’17) y este es el título de la demo que hemos presentado.
Estos días estoy en Oporto, en el 15th International Conference on Practical Applications of Agents and Multi-Agent Systems (PAAMS’17) y este es el título de la demo que hemos presentado.
Se trata de la extensión de una herramienta de análisis de redes sociales, denominada uTool, para incluir análisis de conversaciones y también de sentimientos a partir de la actividad geolocalizada de los usuarios de redes sociales.
Se trata de una herramienta que pretende analizar la actividad en una ciudad a partir de las interacciones que se establecen entre los usuarios de Twitter. En esta demo se han presentado las dos ampliaciones realizadas en los últimos meses.
Por un lado, el análisis de las conversaciones que se producen en las redes en relación a un tema de conversación o dentro de un área determinado. La mayoría de las aplicaciones actuales se limitan a medir impactos globales, estudiando el alcance de las publicaciones, el número total de impresiones o la cantidad de retuits. En nuestro caso, analizamos las interacciones explícitas entre los usuarios. Para ello, estudiamos las menciones, es decir, cuando el nombre de un usuario aparece contenido en el texto del tuit. Esto se produce cuando se responde a un tuit anterior (respuesta), se retuitea o simplemente se desea nombrar a alguien para iniciar una conversación. Normalmente, estos tuits tienen una mayor visibilidad pues activan notificaciones o están disponibles en un apartado especial de las herramientas de escritorio o de las aplicaciones móviles. Para estudiar su impacto, se construye la red a partir de las menciones y se realizan las medidas habituales en el análisis de redes sociales: distribución del grado, diámetro, camino mínimo medio, clustering, distintas medidas de centralidad, detección de comunidades, etc.
El artículo completo está disponible a través de la siguiente referencia
Vivanco E., Palanca J., del Val E., Rebollo M., Botti V. (2017) Using Geo-Tagged Sentiment to Better Understand Social Interactions. In: Demazeau Y., Davidsson P., Bajo J., Vale Z. (eds) Advances in Practical Applications of Cyber-Physical Multi-Agent Systems: The PAAMS Collection. PAAMS 2017. Lecture Notes in Computer Science, vol 10349. Springer, Cham
Por otra parte, se incluye un módulo de análisis de sentimientos básicos. La herramienta permite cargar un mapa con polígonos, de manera que se acumulan los sentimientos detectados en todos los tuits que caen dentro de cada polígono. De esta forma, es posible identificar el sentimiento mayoritario en distintas zonas de la ciudad (barrios, distritos…) Con este proceso es posible detectar puntos en los que exista descontento entre los ciudadanos, por ejemplo por un fallo en el transporte público, un mal servicio de salud o deficiencias en las infraestructuras. También se identifican las zonas con un sentimiento positivo o neutro,
La entrada Using geo-tagged sentiment to better understand social interactions se publicó primero en Miguel Rebollo.
↧
Narrativa transmedia en el aula
 Del día 28 al 30 de junio se ha celebrado en Valencia el III Simposio Internacional de Innovación Aplicada (IMAT ’17), en el que me invitaron a participar (gracias a María Guijarro por la invitación). En el campo de la innovación educativa, un tema en el que hemos empezado a trabajar desde el EICE al que pertenezco, es el uso de las narrativas transmedia en el aula. Y ese fue el tema de mi charla.
Del día 28 al 30 de junio se ha celebrado en Valencia el III Simposio Internacional de Innovación Aplicada (IMAT ’17), en el que me invitaron a participar (gracias a María Guijarro por la invitación). En el campo de la innovación educativa, un tema en el que hemos empezado a trabajar desde el EICE al que pertenezco, es el uso de las narrativas transmedia en el aula. Y ese fue el tema de mi charla.
El uso del término narrativa transmedia aparece por primera vez en un artículo de Henry Jenkins en el año 2003 titulado Transmedia Storytelling. En él habla de la segregación del mensaje en distintos medios y de la participación de la audiencia como pilares fundamentales.
Existen numerosos casos de mundos transmedia: Star Wars, Star Trek, Harry Potter, Perdidos, Pokémon, Resident Evil, Batman y un largo etcétera, a partir de productos diversos: películas, series de televisión, libros, cómics, videojuegos… Y, como no, para mi un ejemplo obligatorio y del que me declaro fan absoluto: El Ministerio del Tiempo; una obra que se planteó como un producto televisivo “tradicional”, abierto a as redes sociales, pero que a partir de la segunda temporada comenzó a explorar las posibilidades transmedia y ahora las acciones transmedia de MdT son una parte indispensable de la serie.
La narrativa transmedia no es un fenómeno exclusivo de la ficción. Podemos encontrar obras que s enmarcan dentro del periodismo o de los documentales transmedia, que surgen con fines informativos, divulgativos, formativos o para concienciar al público de determinadas situaciones. Aquí en ocasiones es difícil separar la linea de lo que son productos multimedia (documedia o documentales interactivos) como el caso de Snow Fall, del Ney York Times (ganador de un premio Pulitzer) o los documentales del Nacional Film board de Canadá que surgen a parir de Highrise. Aunque aquí también se encuentran obras realmente transmedia, como Mujeres en venta, sobre la desaparición y trata de blancas en Argentina.
Este último tipo de narrativa transmedia de no ficción es el que más se acerca a los procesos que tienen lugar en el aula, en los que no hay una historia o un personaje alrededor del cuál construir el mundo transmedia.
La entrada Narrativa transmedia en el aula se publicó primero en Miguel Rebollo.
↧
More Pages to Explore .....








